M5Stack + Module LLM を使ってみた

対象者
- Arduino IDE / PlatformIO で M5Stack の開発をしたことがある
- Module LLM をとりあえず使ってみたい、何ができるか知りたい
必要なもの

写真は M5Stack CoreS3 に Module LLM、バッテリーボトムをスタックしたものです。
概要
Module LLM は M5Stack にスタックして使うことができる AI 処理用のモジュールです。名称にある LLM (Large Language Model) に限らず、画像処理や音声認識、音声合成などの AI 処理をおこなうことができる、AXERA AX630C プロセッサと 4GB のメモリー等を備えた Linux サーバーです。
このモジュールを使うことで、インターネットに接続してクラウドサービスを使用する代わりに、デバイス内で AI 処理をおこなうことができます。Module LLM には M5Stack 用に開発された StackFlow というフレームワークがインストールされており、シリアル通信やネットワークを通したメッセージ通信によって機能を利用します。購入した状態でも基本のモデルがインストール済みのため、すぐに試すことができます。
ファームウェア
参考) Module LLM ファームウェアアップグレードガイド
購入時にプリインストールされていますが古くて不安定だったりする可能性があるので、できれば最新版にアップデートして使うのが良いと思います。壊してしまった場合の復旧手段にもなります。このステップは省略しても構いません。
Module LLM と PC を接続するためには、Android SDK Platform-Tools をインストールしておきます。USB ケーブルで PC と接続し、PC 側で adb devices コマンドを実行して、接続されていることを確認します。
$ adb devices
List of devices attached
axera-ax620e device
ファームウェアファイルを上記の公式ページからダウンロードしておきます。 例) M5_LLM_ubuntu2022-02_20241203-mini.axp
Windows の場合は AXDL というアプリケーションを使って手順どおりにします。macOS/Linux の場合は、GitHub から axdl_tool.py をダウンロードして使います。使い方はファイル内に書いてありますが、以下は macOS の場合の手順です。ブートボタンを押しながら USB ケーブルを接続して電源を入れ、コマンドを実行します。(余談ですが公式手順の写真、ブートボタンが基板上にあるのかと思って探してしまいました。普通に外から押せるボタンのことですね..)
brew install libusb
pip install pyusb tqdm
sudo python3 axdl_tool.py --axp (ダウンロードしたファームウェアファイル)
デバッグボードなどを使って Module LLM がインターネットされた状態であれば、コンソールにログインし、以下の手順で各種パッケージを最新版に更新することができます。
wget -qO /etc/apt/keyrings/StackFlow.gpg https://repo.llm.m5stack.com/m5stack-apt-repo/key/StackFlow.gpg
echo 'deb [arch=arm64 signed-by=/etc/apt/keyrings/StackFlow.gpg] https://repo.llm.m5stack.com/m5stack-apt-repo jammy ax630c' > /etc/apt/sources.list.d/StackFlow.list
apt update
apt upgrade
ライブラリ
M5Stack から Module LLM の StackFlow を利用するライブラリ m5stack/M5Module-LLM by M5Stack が用意されています。
参考)
Arduino IDE
Arduino IDE の場合は、ライブラリマネージャから検索してインストールします。
PlatformIO
PlatformIO の場合は platformio.ini に追記します。
lib_deps =
m5stack/M5Module-LLM@^1.5.0
Module LLM の初期化
Module LLM を使用する際の共通の初期化方法です。機種ごとに指定するポート番号は異なるので、それぞれ適切なポート番号を指定します。
#include <M5ModuleLLM.h>
M5ModuleLLM module_llm;
void setup() {
// Serial2.begin(115200, SERIAL_8N1, 16, 17); // Basic
// Serial2.begin(115200, SERIAL_8N1, 13, 14); // Core2
Serial2.begin(115200, SERIAL_8N1, 18, 17); // CoreS3
module_llm.begin(&Serial2);
// 接続待ち
while (true) {
if (module_llm.checkConnection()) {
break;
}
}
// リセット
module_llm.sys.reset();
...
}
LLM (Large Language Model)
参考) examples/TextAssistant/TextAssistant.ino
ChatGPT のように、自然言語による質問に対して応答を返します。デフォルトのモデルは Qwen2.5 (qwen2.5-0.5b) です。
#include <M5ModuleLLM.h>
M5ModuleLLM module_llm;
String llm_work_id;
void setup() {
...
// Setup LLM
m5_module_llm::ApiLlmSetupConfig_t llm_config;
llm_work_id = module_llm.llm.setup(llm_config, "llm_setup");
if (llm_work_id.isEmpty()) {
// エラー
}
}
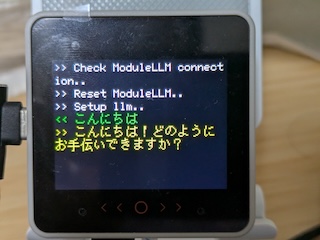
module_llm.llm.inferenceAndWaitResult() を呼ぶと、質問の回答をコールバック関数で受信することができます。
String question = "こんにちは";
module_llm.llm.inferenceAndWaitResult(llm_work_id, question.c_str(), [](String& result) {
M5.Display.printf(">> %s", result.c_str());
});
TTS (Text to Speech)
サンプル) examples/main/examples/TTS/TTS.ino
テキストから音声データを生成するモデルです。デフォルトのモデルは single_speaker_english_fast です。
#include <M5ModuleLLM.h>
M5ModuleLLM module_llm;
String audio_work_id;
String tts_work_id;
void setup() {
...
// Setup Audio
audio_work_id = module_llm.audio.setup();
if (audio_work_id.isEmpty()) {
// エラー
}
// Setup TTS
m5_module_llm::ApiTtsSetupConfig_t tts_config;
tts_work_id = module_llm.tts.setup(tts_config, "tts_setup", "en_US");
if (tts_work_id.isEmpty()) {
// エラー
}
}
module_llm.tts.inference() を呼ぶだけでしゃべってくれます。シンプル!
module_llm.tts.inference(tts_work_id, "Hello!", 10000);
MyShell.ai が開発している TTS モデルを使う場合は module_llm.melotts を使用します。多言語対応のモデルですが、StackFlow 版は日本語には対応していないようです。
ASR (Automated Speech Recognition) / STT (Speech to Text)
マイクから拾った音声をテキストに変換するモデルです。デフォルトのモデルは sherpa-ncnn (sherpa-ncnn-streaming-zipformer-20M-2023-02-17) です。
デフォルトでは KWS と併用してウェイクワードを検出してから音声認識をおこないますが、enkws に false を指定することで単体で継続して音声認識することができます。
#include <M5ModuleLLM.h>
M5ModuleLLM module_llm;
String asr_work_id;
void setup() {
...
// Setup ASR
m5_module_llm::ApiAsrSetupConfig_t asr_config;
asr_config.enkws = false;
asr_work_id = module_llm.asr.setup(asr_config, "asr_setup", "en_US");
if (asr_work_id.isEmpty()) {
// エラー
}
}
認識結果は module_llm.msg.responseMsgList からメッセージを取り出して処理します。認識の途中経過も何度か繰り返し返ってきますが、最終的な結果は finish フラグが立ってくるのでそれだけ読めば良いです。
また動作させてみたところひとつのメッセージ (raw_msg) に複数のメッセージが入ってくることもあるようだったので、サンプルコードに加えて改行で区切って処理する必要がありそうです。(splitLines() は文字列を改行で分割する自作関数ですが省略しています。)
void loop() {
module_llm.update();
for (auto &msg: module_llm.msg.responseMsgList) {
if (msg.work_id == asr_work_id) {
if (msg.object == "asr.utf-8.stream") {
for (const auto &one: splitLines(msg.raw_msg.c_str())) {
JsonDocument doc;
deserializeJson(doc, one.c_str());
if (doc["data"]["finish"].as<bool>()) {
// 最終結果を取得
String asr_result = doc["data"]["delta"].as<String>();
M5.Display.printf(">> %s\n", asr_result.c_str());
}
}
}
}
}
module_llm.msg.responseMsgList.clear();
}
ただ、モデルのせいかマイクのせいか発音が悪いせいか分かりませんが、なかなか思ったように認識してくれない感じはしました。
KWS (KeyWord Spotting)
参考) examples/KWS_ASR/KWS_ASR.ino
ウェイクワードを検出するモデルです。デフォルトのモデルは sherpa-onnx (sherpa-onnx-kws-zipformer-gigaspeech-3.3M-2024-01-01) です。
KWS を設定後、ASR の設定に KWS の work_id を指定することで、ウェイクワードを検出後に音声認識をおこなうようになります。ウェイクワードは大文字で指定します。
String kws_work_id;
String asr_work_id;
void setup() {
...
// Setup KWS
m5_module_llm::ApiKwsSetupConfig_t kws_config;
kws_config.kws = "HELLO"; // ウェイクワード
kws_work_id = module_llm.kws.setup(kws_config, "kws_setup", "en_US");
if (kws_work_id.isEmpty()) {
// エラー
}
// Setup ASR
m5_module_llm::ApiAsrSetupConfig_t asr_config;
asr_config.input = {"sys.pcm", kws_work_id};
asr_work_id = module_llm.asr.setup(asr_config, "asr_setup", "en_US");
if (asr_work_id.isEmpty()) {
// エラー
}
}
ASR だけの場合と同じく、module_llm.msg.responseMsgList から結果を取り出して処理します。
void loop() {
module_llm.update();
for (auto &msg: module_llm.msg.responseMsgList) {
if (msg.work_id == kws_work_id) {
// ウェイクワードを検出した
M5.Display.printf(">> Keyword detected\n");
} else if (msg.work_id == asr_work_id) {
// 音声認識
if (msg.object == "asr.utf-8.stream") {
for (const auto &one: splitLines(msg.raw_msg.c_str())) {
JsonDocument doc;
deserializeJson(doc, one.c_str());
if (doc["data"]["finish"].as<bool>()) {
String asr_result = doc["data"]["delta"].as<String>();
M5.Display.printf(">> %s\n", asr_result.c_str());
}
}
}
}
}
module_llm.msg.responseMsgList.clear();
}
検出するとおっさんの声で「Hi」と返ってきてびびりました。これカスタマイズできないのかな?
VoiceAssistant
参考) examples/VoiceAssistant/VoiceAssistant.ino
これまで出てきたモデルを使って以下の一連の処理をおこない、音声アシスタントを作成するライブラリです。
- KWS でウェイクワード検出
- ASR で音声認識
- LLM で問い合わせ
- TTS で回答
初期化
M5ModuleLLM module_llm;
M5ModuleLLM_VoiceAssistant voice_assistant{&module_llm};
void setup() {
// Serial2.begin(115200, SERIAL_8N1, 16, 17); // Basic
// Serial2.begin(115200, SERIAL_8N1, 13, 14); // Core2
Serial2.begin(115200, SERIAL_8N1, 18, 17); // CoreS3
module_llm.begin(&Serial2);
// Setup VoiceAssistant
int ret = voice_assistant.begin("HELLO"); // ウェイクワード
if (ret != MODULE_LLM_OK) {
// エラー
}
}
して、ループを呼ぶだけです。
void loop() {
voice_assistant.update();
}
コールバック関数を登録してイベントを処理することもできます。
void setup() {
...
// Setup callback
voice_assistant.onAsrDataInput([&](const String &data, bool isFinish, int index) {
if (isFinish) {
M5.Display.setTextColor(TFT_GREEN, TFT_BLACK);
M5.Display.printf(">> %s\n", data.c_str());
}
});
voice_assistant.onLlmDataInput([&](const String &data, bool isFinish, int index) {
M5.Display.setTextColor(TFT_YELLOW, TFT_BLACK);
M5.Display.print(data);
if (isFinish) {
M5.Display.print("\n");
}
});
}
onAsrDataInput() は ASR の音声認識結果、onLlmDataInput() は LLM の回答を受け取ります。
YOLO (You Only Look Once) 物体検知
Module LLM に USB カメラを接続して、物体検知をおこなうことができます。
M5ModuleLLM module_llm;
String camera_work_id;
String yolo_work_id;
void setup() {
...
// Setup Camera
camera_work_id = module_llm.camera.setup();
if (camera_work_id.isEmpty()) {
// エラー
}
// Setup YOLO
m5_module_llm::ApiYoloSetupConfig_t yolo_config;
yolo_config.input = {camera_work_id};
yolo_work_id = module_llm.tts.setup(yolo_config, "yolo_setup");
if (yolo_work_id.isEmpty()) {
// エラー
}
}
フレームごとに物体検知結果がじゃんじゃん送られてきます。座標は 320x320 の範囲で送られてくるので、M5Stack の画面サイズに合わせて描画してみました。映像自体は Module LLM 内で処理されるため、取得できません。
void loop() {
float rw = M5.Display.width() / 320.0;
float rh = M5.Display.height() / 320.0;
M5.Display.clear();
module_llm.update();
for (auto &msg: module_llm.msg.responseMsgList) {
if (msg.work_id == yolo_work_id) {
if (msg.object == "yolo.box.stream") {
for (const auto &one: splitLines(msg.raw_msg.c_str())) {
JsonDocument doc;
deserializeJson(doc, one.c_str());
auto delta = doc["data"]["delta"].as<JsonObject>();
auto bbox = delta["bbox"].as<JsonArray>();
auto cls = delta["class"].as<String>();
auto confidence = delta["confidence"].as<String>();
if (bbox.size() == 4) {
int x1 = bbox[0].as<float>() * rw;
int y1 = bbox[1].as<float>() * rh;
int x2 = bbox[2].as<float>() * rw;
int y2 = bbox[3].as<float>() * rh;
M5.Display.clear();
M5.Display.drawRect(x1, y1, x2 - x1, y2 - y1, TFT_GREEN);
M5.Display.setCursor(x1, y1 - 20);
M5.Display.setTextColor(TFT_GREEN);
M5.Display.printf("%s: %s", cls.c_str(), confidence.c_str());
}
}
}
}
}
module_llm.msg.responseMsgList.clear();
}
M5Stack CoreS3 のカメラの画像で物体検知
M5Stack CoreS3 のカメラを使っても物体検知をおこなってみました。
camera_work_id を指定せずに初期化します。
M5ModuleLLM module_llm;
String yolo_work_id;
void setup() {
...
// Setup YOLO
m5_module_llm::ApiYoloSetupConfig_t yolo_config;
yolo_work_id = module_llm.tts.setup(yolo_config, "yolo_setup");
if (yolo_work_id.isEmpty()) {
// エラー
}
}
カメラからフレームデータを取得し、JPEG 形式に変換して Module LLM に送信します。320x240 を画像を送ると 320x320 に拡張されて処理されるようなので、Y 座標を 40 ピクセルずらして描画しています。またデータの転送に時間がかるようなので、Quality を 20 まで落としています。それでも遅延がけっこうあり、実用には厳しそうです。
void loop()
{
uint8_t* jpg_buf;
size_t jpg_size;
if (CoreS3.Camera.get()) {
frame2jpg(CoreS3.Camera.fb, 20, &jpg_buf, &jpg_size);
bool draw = false;
module_llm.yolo.inferenceAndWaitResult(yolo_work_id, jpg_buf, jpg_size, [&](const String& result) {
if (!draw) {
M5.Display.pushImage(0, 0, M5.Display.width(), M5.Display.height(),
reinterpret_cast<uint16_t*>(CoreS3.Camera.fb->buf));
draw = true;
}
for (const auto& one : splitLines(result.c_str())) {
JsonDocument doc;
deserializeJson(doc, one.c_str());
auto bbox = doc["bbox"].as<JsonArray>();
if (bbox.size() == 4) {
int x1 = bbox[0].as<float>();
int y1 = bbox[1].as<float>() - 40;
int x2 = bbox[2].as<float>();
int y2 = bbox[3].as<float>() - 40;
auto cls = doc["class"].as<String>();
auto confidence = doc["confidence"].as<String>();
M5.Display.drawRect(x1, y1, x2 - x1, y2 - y1, TFT_GREEN);
M5.Display.setCursor(x1, y1 - 20);
M5.Display.setTextColor(TFT_GREEN);
M5.Display.printf("%s: %s", cls.c_str(), confidence.c_str());
}
}
});
free(jpg_buf);
CoreS3.Camera.free();
}
delay(10);
}
さいごに
とりあえず Module LLM の基本的な使い方を試してみました。ときどき動かなくなったと思ったらセットアップに失敗していたことがあったりしてハマりました。エラーチェックはちゃんとやっておいた方が良さそうです。
ここからはモデルを新しくしたり、日本語対応したり、いろいろ試していきたいと思います!